
Wir haben im März 18.000 Flyer für einen DACH-Produktlaunch gedruckt. Ein Short Link auf der Rückseite, drei regionale Landing Pages, auf die wir Leute schicken wollten: /de für deutsche Besucher, /fr für den kleinen französischen Anteil, /en für alle anderen. Der Marketing-Lead stellte die offensichtliche Frage: Drucken wir drei Flyer oder einen?
Du druckst einen. Der Link macht das Routing.
Ein "Smart Link" ist eine einzelne kurze URL, deren Ziel beim Redirect berechnet wird, nicht beim Anlegen des Links. Es gibt einen Slug. Es gibt mehrere mögliche Ziele. Die Entscheidung fällt im selben Handler, der sonst ein einfaches 302 ausgegeben hätte - kein separater Service zum Aufrufen, kein JS-Shim auf einer Landing Page, kein zusätzlicher Hop. Dieser Beitrag handelt davon, wie das tatsächlich unter der Haube aussieht, welche sechs Dimensionen Elido beim Routing nutzt und in welchen Fällen du stattdessen zu einem anderen Tool greifen solltest.
Drei Dinge, die ein Smart Link nicht ist#
Leute kommen zu Smart Links aus drei unterschiedlichen Vorerfahrungen, und die Trade-offs sind in jedem Fall anders.
Einfacher Redirect. Ein Slug, ein Ziel, null Logik. Der Redirect-Handler macht ein Cache-Lookup und schreibt ein 302. Du kannst ihn bei der Latenz nicht schlagen; du kannst ihn aber auch nicht bedingt machen. Das ist der Boden - alles, was raffinierter ist, kostet etwas.
Smart Link am Edge. Ein Slug, mehrere mögliche Ziele, ein winziger Regel-Auswertungsschritt, eingefügt zwischen dem Cache-Lookup und der Antwort. Weil die Regel im selben Prozess wie der Cache-Lookup lebt, sind die Kosten im Sub-Millisekunden-Bereich (0,3ms p50 / 1ms p95 in Elidos Fall). Der Besucher sieht einen HTTP-Round-Trip. Der Browser-Cache wird nicht vergiftet, weil 302-Antworten gemäß RFC 7234 §4.2.2 standardmäßig nicht cacheable sind - eine Tatsache, die hier wichtig ist, denn Per-Request-Routing ergibt nur Sinn, wenn jeder Request sein eigenes Ziel wählen darf.
JavaScript-A/B-Router auf einer Landing Page. Eine neutrale HTML-Seite rendert, JS prüft navigator.userAgent oder einen Geo-IP-Dienst, dann window.location = '/foo'. Das ist die schlechteste der drei Optionen. Der Besucher sieht einen HTML-Render, dann einen Redirect, dann die eigentliche Seite - mindestens ein zusätzlicher Round-Trip, oft zwei, wenn das Geo-Lookup von einem Drittanbieter kommt. Die SEO-Indexierung wird vermatscht, weil Crawler die neutrale Seite sehen. Cookie-blockierende Browser und Privacy-Erweiterungen brechen die JS-Hälfte. Apples Release-Notes zu Intelligent Tracking Prevention 2.3 heben genau dieses Muster hervor: Client-seitige Tracking-Links via Document-Referrer werden gedrosselt, und die Abhilfe erfordert serverseitige Beteiligung. Wenn du heute in JS routest, bezahlst du die Rechnung bereits.
Der richtige Ort, um eine Routing-Entscheidung zu platzieren, ist derselbe Hop, der den Redirect ohnehin ausgibt. Genau das tun Edge-Smart-Links.
Warum es am Edge lebt - das Latenz-Budget#
Die Elido-Redirect-Schicht hat ein hartes Latenz-Budget: p50 5ms, p95 15ms bei einem Cache-Hit, ausgenommen TLS-Handshake. Diese Zahl ist nicht ambitioniert - alles, was uns darüber drückt, wird rausgerissen. Synchrones SQL auf dem Hot Path, Regex-Kompilation pro Request, blockierende I/O beim Click-Event: alles weg, alles in Cold-Path-Worker verschoben.
Die zwei Gründe, warum dieses Budget existiert:
- Mobilfunknetze fügen ihre eigene Steuer hinzu. Apples "Reducing Network Latency"-Guide durchgeht, wie sich Verzögerungen in Mobilfunknetzen über Redirect-Ketten kumulieren. Jeder zusätzliche Hop fügt RTT hinzu, die das Netz des Besuchers bereits aufgebläht hat. Je weniger Hops wir hinzufügen, desto weniger bestraft ihr Netz sie.
- Edge-Nähe ist der eigentliche Hebel. Cloudflares Primer zu Edge-Side-Routing rahmt es genauso: Die billigste Entscheidung ist die, die im selben Prozess wie der Response-Writer getroffen wird, im POP, der dem Besucher am nächsten ist. Wir sind nicht einzigartig darin, Edge-Routing zu betreiben; einzigartig ist, es in den URL-Shortener zu bündeln, statt dich zu bitten, eine separate Workers- / Lambda@Edge-Funktion zu deployen.
Wenn wir die Regel-Auswertung an einen nachgelagerten Service auslagerten - sagen wir, eine hypothetische "rules-api", erreichbar über HTTP - würden wir bei jedem Request einen Same-Region-Round-Trip hinzufügen. In der Region sind das mindestens etwa 5ms (ein Same-Region-Hop über ein privates Netz), und im regionsübergreifenden Verkehr geht das Tail sehr schnell hässlich aus. Die 15ms p95 überleben den Round-Trip nicht. Also sind Smart-Link-Regeln inline, in der Edge-Binary, und werden gegen kompilierte Matcher ausgewertet, die gebaut wurden, als der Link in den Cache geladen wurde. Die gesamte Regel-Engine umfasst etwa 400 Zeilen Go.
Diese enge Kopplung ist auch der Grund, warum wir Echtzeit-Regeländerungen machen können: Regeländerungen propagieren via einen Pub/Sub-Kanal des In-Memory-Cache (link:invalidate), den jeder Edge-POP abonniert. Der L1-LRU evictet innerhalb einer Sekunde nach dem Publish, der nächste Request befüllt aus L2 neu, und die neue Regel ist live. Mehr dazu weiter unten.
Die sechs Routing-Dimensionen#
Elido-Smart-Links matchen auf sechs Dinge. Jedes ist auf einen spezifischen Input gemappt, auf den der Edge pro Request Zugriff hat.
Land. Zweistelliges ISO 3166-1 alpha-2, aus der IP des Besuchers via Geoip abgeleitet. Nützlich, wenn du regionale Storefronts hast und der Conversion-Uplift pro Land die Routing-Komplexität wert ist. Der klassische Stolperstein hier sind Reisende - ein Deutscher im Spanien-Urlaub trifft das spanische Ziel, wenn du nur nach Land routest. Wenn die Sprachpräferenz wichtiger ist als der geografische Standort, route stattdessen auf languages. Wir diskutieren den vollständigen Geoip-Flow im Analytics-Privacy-Post - die IP wird vor der Speicherung gekürzt, sodass die DSGVO-Seite sauber bleibt.
Gerät. mobile, tablet, desktop, beim Request aus dem User-Agent-String geparst. Der Use Case, für den Marketer dazu greifen: App-Install-Banner, die auf iOS zum App Store gehen, auf Android zum Play Store und auf Desktop zu einer Marketing-Seite. Worauf zu achten ist: User-Agent-Strings auf dem iPad sind ein bewegliches Ziel, seit iPadOS standardmäßig den Desktop-Safari-UA präsentiert, und unsere Tablet-Erkennung berücksichtigt das, aber sie ist nicht auf jeder Browser-Version 100%. Wenn der Unterschied zwischen Tablet- und Desktop-Traffic für dich in Euro zählt, instrumentiere das Ziel und verifiziere.
OS. ios, android, macos, windows, linux. Dieselbe User-Agent-Quelle wie Gerät, engere Partition. Der Deep-Link-Fall: iOS-Besucher zu einem Universal Link routen, das die App abfängt und auf den App Store zurückfällt; Android mit erhaltenen Referrer-Daten zum Play Store routen. Dafür haben wir die Apple-App-Site-Association-Integration gebaut.
Sprache. Primärer Sprach-Tag aus dem Accept-Language-Header des Besuchers. ISO-639-1-Codes wie de, fr, pt. Die Falle: Accept-Language ist die Browser-Präferenz, die oft nicht mit dem IP-Geo übereinstimmt. Ein französischer Expat in Berlin bekommt country: DE, languages: ["fr", "en"] - wenn du ihn auf /fr willst, route auf Sprache; wenn du ihn auf der deutschen Storefront willst, weil du lokalisierte Preise A/B-testest, route auf Land. Sequenziere die Regeln entsprechend.
Tageszeit und Wochentag. HH:MM-Fenster in einer beliebigen IANA-Zeitzone, plus ein days_of_week-Bitmap. Zeitfenster-Deals - eine "Happy-Hour"-Landing-Page, die Mo–Fr um 17:00 Europe/Berlin live geht und außerhalb dieses Fensters auf die reguläre Seite zurückfällt - sind der natürliche Fit. Das time_start / time_end-Fenster unterstützt Wraparound (22:00 → 02:00), was offensichtlich klingt, uns aber erwischt hat, als wir die Regel-Engine vom Prototyp portiert haben, der das nicht handhabte. Das vollständige Schema ist in der Smart-Links-Anleitung.
Referrer-Host. Der Hostname-Teil des Referer-Headers, normalisiert. Nützlich für partnerbewusste Ziele: Besucher, die von partner.example ankommen, bekommen eine co-branded Landing Page; alle anderen bekommen den Default. Weniger nützlich als früher - moderne Browser strippen Referer aggressiv, wenn die verweisende Seite Referrer-Policy: no-referrer setzt oder wenn die Navigation HTTPS-Kontexte auf eine Art überquert, die die Policy nicht erlaubt. Behandle Referrer-Regeln als weiches Signal, nie als Authentifizierung.
Das ist die Liste. Sechs Dimensionen decken die Marketing-Routing-Entscheidungen ab, die wir in drei Jahren Kundengesprächen gesehen haben. Die bewussten Auslassungen sind Nutzer-Identität (die kennen wir beim Redirect nicht), beliebige HTTP-Header (das Kosten-Nutzen-Verhältnis ist für die wenigen Teams, die danach gefragt haben, nicht da) und randomisierte Splits (nutze stattdessen Variant-Rotation, das ist ein separates Feature).
First-Match-Semantik; Fallback immer erforderlich#
Regeln sind ein Array. Der Edge geht sie in Reihenfolge durch. Die erste Regel, deren match-Block vollständig erfüllt ist, gewinnt, und ihre destination_url ist das Redirect-Ziel. Die destination_url auf der obersten Ebene des Links ist der unbedingte Fallback. Wir weigern uns, einen Smart Link ohne einen zu erstellen - ein Smart Link erzeugt by design nie einen 404.
Die minimal lebensfähige Form:
{
"destination_url": "https://acme.example/en",
"targeting_rules": [
{
"match": { "countries": ["DE", "AT", "CH"] },
"destination_url": "https://acme.example/de"
},
{
"match": { "languages": ["fr"] },
"destination_url": "https://acme.example/fr"
}
]
}
DACH-Besucher treffen /de, weil Regel 1 zuerst matcht. Ein französischer Expat in Berlin hat country=DE, also trifft er auch /de - Regel 1 matcht, bevor Regel 2 eine Chance bekommt. Wenn du den französischen Expat auf /fr willst, vertausche die Regeln, sodass die Sprachregel zuerst geprüft wird. Die Reihenfolge im Dashboard ist die Reihenfolge, in der wir auswerten.
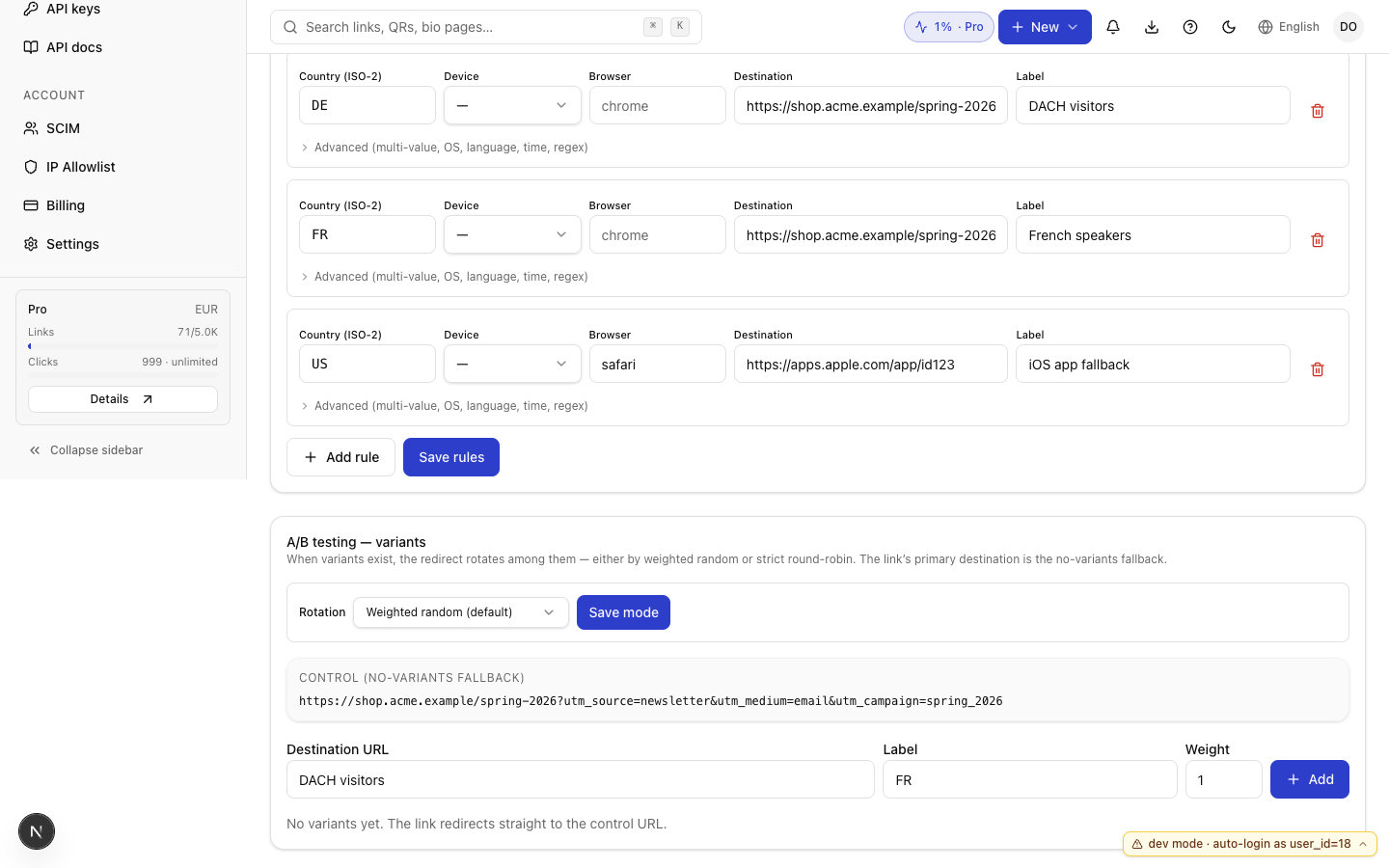
Zwei Dinge, die das impliziert und es wert sind, laut ausgesprochen zu werden:
- Breitere Regeln kommen zuletzt. Eine Regel ohne
match-Bedingungen matcht alles; wenn sie an erster Stelle steht, feuert keine darunter liegende Regel mehr. Das Dashboard validiert dagegen und warnt dich, aber die API tut das nicht, also brauchen skriptgebaute Regeln einen Sanity-Check. - Gegenseitiger Ausschluss liegt bei dir. Wenn zwei Regeln beide einen einzelnen Besucher matchen, gewinnt die erste stillschweigend. Es gibt keinen Fehler, keine Flagge, keine Metrik. Wir haben in Erwägung gezogen, beim Link-Load eine Warnung auszugeben, wenn zwei Regeln als überlappend erkennbar sind, und das ist für das nächste Minor-Release auf der Roadmap. Vorerst: Lies deine Regeln von oben nach unten und vertraue der Reihenfolge.
Die Kosten: Cache-Invalidation-Propagation#
Jede Routing-Entscheidung hat ein Propagation-Fenster. Im Dashboard bearbeitete Smart-Link-Regeln propagieren auf dem Happy Path in etwa 1 Sekunde durch die L1-Caches an allen drei Elido-POPs. Etwa, weil:
- Der L1-LRU an jedem POP hält regeltragende Links mit einer 60-Sekunden-TTL (die Cache-Architektur ist hier dokumentiert). Die TTL ist die Obergrenze - selbst ohne ein Invalidate-Publish ist ein veralteter Eintrag innerhalb einer Minute weg.
- Das Invalidate-Publish läuft über das Pub/Sub des In-Memory-Cache. Die EU- und US-East-POPs teilen sich einen Cache-Cluster; Asien-Pazifik hat seinen eigenen. Cross-Region-Propagation ist im Wesentlichen Cache-Replikationslatenz plus die Pub/Sub-Verarbeitung unseres Subscribers, die in unseren Metriken im letzten Quartal unter 1 Sekunde p99 lag.
- Ein POP, der sein Cache-Abonnement verloren hat, fällt auf die 60-Sekunden-TTL zurück. Wir alarmieren bei Abonnement-Verlust; der On-Call hat 5 Minuten gepufferte Clicks, bevor das WAL einspringt.
Übersetzung: Für Marketing-Flows, bei denen 60 Sekunden veraltetes Routing in Ordnung sind, musst du darüber nicht nachdenken. Für Flows, in denen Veraltung zählt - eine Rotation eines rechtlichen Disclaimers, ein Billing-Cohort-Split, bei dem das falsche Ziel die falsche Währung abrechnet - ist der Spielzug status=disabled zuerst, dann nach einer Minute wieder aktivieren, dann die neue Regel veröffentlichen. Wir haben einen GET /v1/links/{id}/status-Endpunkt hinzugefügt, sodass eine CI-Pipeline darauf pollen kann, dass die Propagation abgeschlossen ist, bevor sie einen Schalter weiter unten umlegt.
Wann man keinen Smart Link nutzt#
Drei Fälle, in denen das richtige Werkzeug kein Smart Link ist.
Serverseitiges Rendering des Ziels ist besser. Wenn die Variante in die HTML-Antwort injiziert werden muss - sagen wir, Preis-Lokalisierung, die vom authentifizierten Zustand des Besuchers abhängt, oder eine Landing Page, die einen kohortenspezifischen Hero aus deinem CMS zieht - dann ist das eine Aufgabe für den Server des Ziels, nicht für den Redirect. Der Redirect wählt, wohin der Besucher geschickt wird; das Ziel wählt, was gerendert wird. Routing-Logik, die am Edge lebt, kann deine Auth-Session nicht sehen, und sie hineinzuwürgen würde entweder erfordern, die Session in den Redirect-Pfad zu lecken (das tun wir nicht) oder durch den Edge zu proxyen (das tun wir wegen des Latenz-Budgets nicht). Rendere Varianten am Origin.
Statistisch rigoroses A/B-Testing. Smart Links routen pro Request, nicht pro Besucher. Wenn ein Besucher zweimal in fünf Minuten vom selben Gerät aus landet, sieht er unter einer randomisierten Regel möglicherweise zwei verschiedene Ziele, was das richtige Verhalten für "schicke 50% des Mobile-Traffics zu A und 50% zu B" ist, aber das falsche Verhalten für "miss, ob Variante A über ein 4-Wochen-Fenster besser konvertiert als Variante B". Für Letzteres brauchst du ein stabiles Varianten-Cookie und ein Experiment-Tool, das die Statistik richtig macht. PostHog, GrowthBook und LaunchDarkly tun das alle. Wir tun das nicht, und wir werden es nicht tun - das Tooling ist ein anderer Job. Nutze Variant-Rotation mit round_robin für Low-Stakes-Sampling und greife zu einer Experiment-Plattform, wenn du das Ergebnis verteidigen musst.
Identitätsbewusstes Routing. Smart Links sind absichtlich zustandslos. Sie werten gegen country | device | OS | language | time | referrer aus und sonst nichts. Wenn du basierend auf der Tier eines eingeloggten Nutzers, seinen Feature-Flags oder irgendetwas, das das Nachschlagen von "wer ist diese Person" erfordert, routen musst, ist der Redirect-Pfad die falsche Schicht. Löse die Identität am Origin auf und liefere die Variante von dort aus. Oder, wenn du wirklich eine Redirect-Zeit-Entscheidung brauchst, präge per-User-Short-Links via die API - jeder authentifizierte Nutzer bekommt seinen eigenen Slug, das Ziel des Slugs ist für diesen Nutzer zur Erstellungszeit korrekt, und du musst nie Identitätsauflösung auf dem Hot Path machen.
Was als Nächstes kommt#
Wenn du die Regelform an deinen eigenen Daten ausprobieren willst, geht die Dokumentations-Anleitung durch das JSON-Schema und den Dashboard-Editor. Der Rule-Builder lebt unter der Edit-Seite eines beliebigen Links im Dashboard - Links → ⋯ → Targeting.
Zwei Verbesserungen, die im nächsten Minor-Release landen: eine Fallback-Hierarchie für languages (sodass pt-BR sauber auf pt herunter degradiert, dann auf en, ohne drei Regeln zu schreiben), und ein Static-Analysis-Pass beim Link-Save, der überlappende Regeln markiert, sodass das Dashboard warnen kann, bevor die Regel live geht. Beide sind Implementierungsarbeit, keine breaking Schema-Änderungen. Wenn du eine Regelform hast, die wir nicht unterstützen, und du denkst, dass wir das sollten, ist der Feedback-Kanal unten auf der Smart-Links-Feature-Seite.
Verwandtes im Blog#
Elido testen
URL einfügen, kurzer Link in Sekunden
Kein Konto nötig. Link bleibt 30 Tage aktiv. Konto erstellen, um ihn dauerhaft zu behalten.
Kostenlos, keine Anmeldung erforderlich · 2 pro Tag